Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
Strojno učenje
Pridobivanje značilnosti
Ko smo si v prejšnjem primeru ogledali skupini A in B, smo verjetno najprej opazili barvo kart. Šele nato pa številko ali črko. Pri algoritmih je treba vse te posamezne značilnosti vnesti posebej. Algoritem ne more samodejno vedeti, kaj je pomembno za dano nalogo.
Pri izbiri značilnosti si morajo programerji zastaviti številna vprašanja. Koliko značilnosti je premalo, da bi bile uporabne? Koliko jih je preveč? Katere značilnosti so pomembne za nalogo? Kakšno je razmerje med izbranimi značilnostmi – ali je ena značilnost odvisna od druge? Ali je z izbranimi značilnostmi mogoče doseči natančen rezultat?
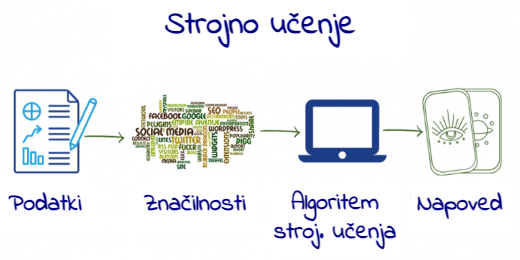
Postopek
Ko programer ustvarja aplikacijo, vzame podatke, iz njih pridobi oziroma izvleče značilnosti, izbere ustrezen algoritem strojnega učenja (matematična funkcija, ki določa postopek) in ga usposobi z uporabo označenih podatkov (v primeru, ko je izhod znan – npr. skupina A ali skupina B), tako da stroj razume vzorec, ki se skriva za problemom.
Za stroj razumevanje pomeni zapis v oblik niza številk ali uteži, ki jih dodeli vsaki značilnosti. S pravilno dodelitvijo uteži lahko izračuna verjetnost, da nova karta spada v skupino A ali B. Običajno v fazi učenja programer pomaga stroju tako, da ročno spremeni nekatere vrednosti (uglaševanje). Za tem je treba program pred začetkom uporabe preizkusiti. Pri tem se vanj vnesejo takšni označeni podatki, ki niso bili uporabljeni v fazi učenja, imenujemo jih testni podatki.
Nato se oceni učinkovitost stroja pri napovedovanju rezultatov. Ko učinkovitost doseže zadovoljivo stopnjo, lahko začnemo z uporabo programa, ki je sedaj pripravljen za vnos povsem novih podatkov, na podlagi katerih sprejema odločitve ali generira napovedi.
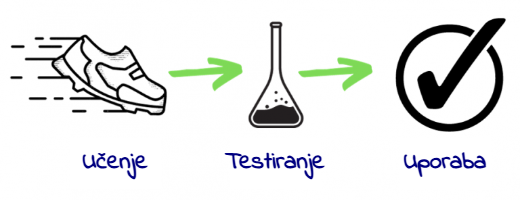
Algoritem nato lastno delovanje v realnem času nenehno spremlja in se izboljšuje (prilagoditev uteži za boljše rezultate). Učinkovitost delovanja v realnem času se pogosto razlikuje od izmerjene učinkovitosti v fazi preizkušanja (testiranja). Ker je eksperimentiranje z resničnimi uporabniki drago, zahteva veliko truda in pogosto s seboj prinaša določeno tveganje, se algoritmi praviloma preizkušajo na podlagi preteklih uporabniških podatkov, zaradi česar pa morda ni možno oceniti vpliva na vedenje uporabnikov. Zato je pomembno, da se pred uporabo aplikacij strojnega učenja opravi celovita ocena njihovega delovanja:
Morajo biti podatki vedno označeni? Preberite več o nadzorovanem, nenadzorovanem in spodbujevanem učenju.