Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
Strojno učenje
Problem klasifikacije
Ena od pogostih nalog, ki se uporablja v aplikacijah strojnega učenja, je klasifikacija. Je na fotografiji pes ali mačka? Ali ima učenec težave pri reševanju nalog, ali je opravil preizkus znanja? Stroj ima na izbiro dve ali več skupin. Aplikacija mora nove podatke razvrstiti v eno od teh skupin.
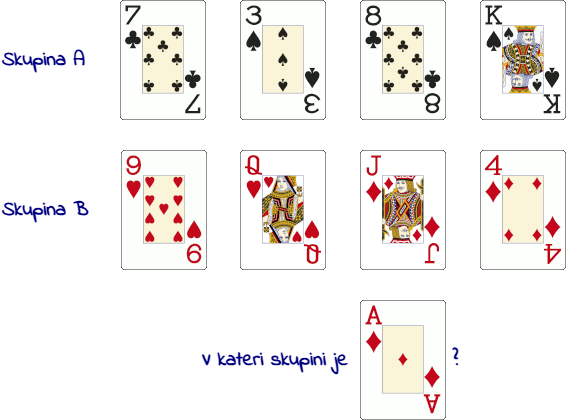
Vzemimo za primer komplet igralnih kart, ki ga po nekem ključu razdelimo na dva kupčka, skupino A in skupino B. Naslednjo karto (karov as) moramo razvrstiti v skupino A ali skupino B.
Najprej moramo razumeti, po kašnem ključu je razdeljen komplet kart – torej potrebujemo primere. Izberemo štiri karte iz skupine A in štiri iz skupine B. Teh osem primerov predstavlja naše učne podatke – podatke, ki nam pomagajo prepoznati vzorec, oziroma, nas s tem »učijo«, kako priti do rezultata.
Takoj ko vidimo razporeditev (gornja slika), nas večina ugane, da karov as spada v skupino B. Pri tem ne potrebujemo posebnih navodil, človeški možgani so čudežni iskalec vzorcev. Kako pa bi to nalogo opravil stroj?
Algoritmi strojnega učenja temeljijo na uveljavljenih statističnih teorijah. Različni algoritmi temeljijo na različnih matematičnih enačbah, ki jih je treba skrbno izbrati, da ustrezajo dani nalogi. Naloga programerja je, da izbere podatke, analizira, katere značilnosti podatkov so pomembne za določen problem, in izbere pravilen algoritem.
Pomen podatkov
Vendar pa bi lahko v omenjenem primeru klasifikacije šlo narobe več stvari. Oglej si spodnjo sliko. V skupini 1 je premalo kart, da bi lahko ugibali. V skupini 2 je sicer več kart, vendar so vse enake barve, zato ne moremo predvideti, kam uvrstiti karo. Če skupine ne bi bile enako velike, bi v skupini 3 karte s številkami spadale v skupino A, karte s podobami pa v skupino B.
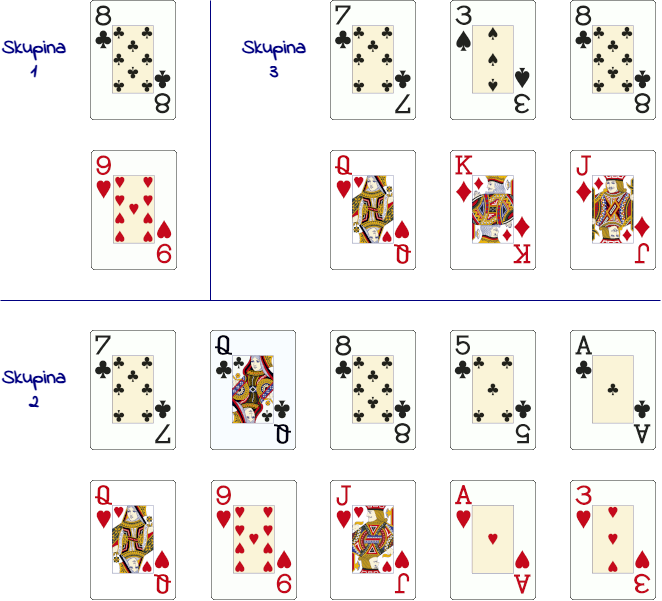
Problemi strojnega učenja so običajno bolj odprti in vključujejo nabore podatkov, veliko večje od kompleta kart. Učne podatke je treba izbrati s pomočjo statistične analize, sicer se vanje prikradejo napake. Dobra izbira podatkov je ključnega pomena za učinkovite aplikacije strojnega učenja, bolj kot pri drugih vrstah programov. Strojno učenje potrebuje veliko število relevantnih podatkov. Osnovni model strojnega učenja mora vsebovati najmanj desetkrat več podatkov, kot je skupno število značilnosti. Kljub temu je strojno učenje posebej primerno tudi za obdelavo neurejenih in nasprotujočih si podatkov.