Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
Umetna inteligenca okoli nas
Druga skrajnost v zvezi z uporabo UI je neselektivna uporaba tehnologije, ali tudi zloraba tehnologije. UI deluje drugače kot človeška inteligenca. Sistemi UI lahko zaradi narave specifičnih okoliščin, zaradi njihove zasnove ali zaradi podatkov samih delujejo drugače od pričakovanega.
Na primer, aplikacija, ki je bila razvita na podlagi določenih podatkov za določen namen, ne bo delovala enako dobro na podlagi drugačnih podatkih za drugačen namen. Dobro je poznati omejitve UI in jih odpraviti. Torej ne moremo preprosto preklopiti na UI, temveč se moramo seznaniti s prednostmi in omejitvami njene uporabe.
Ohranjanje stereotipov
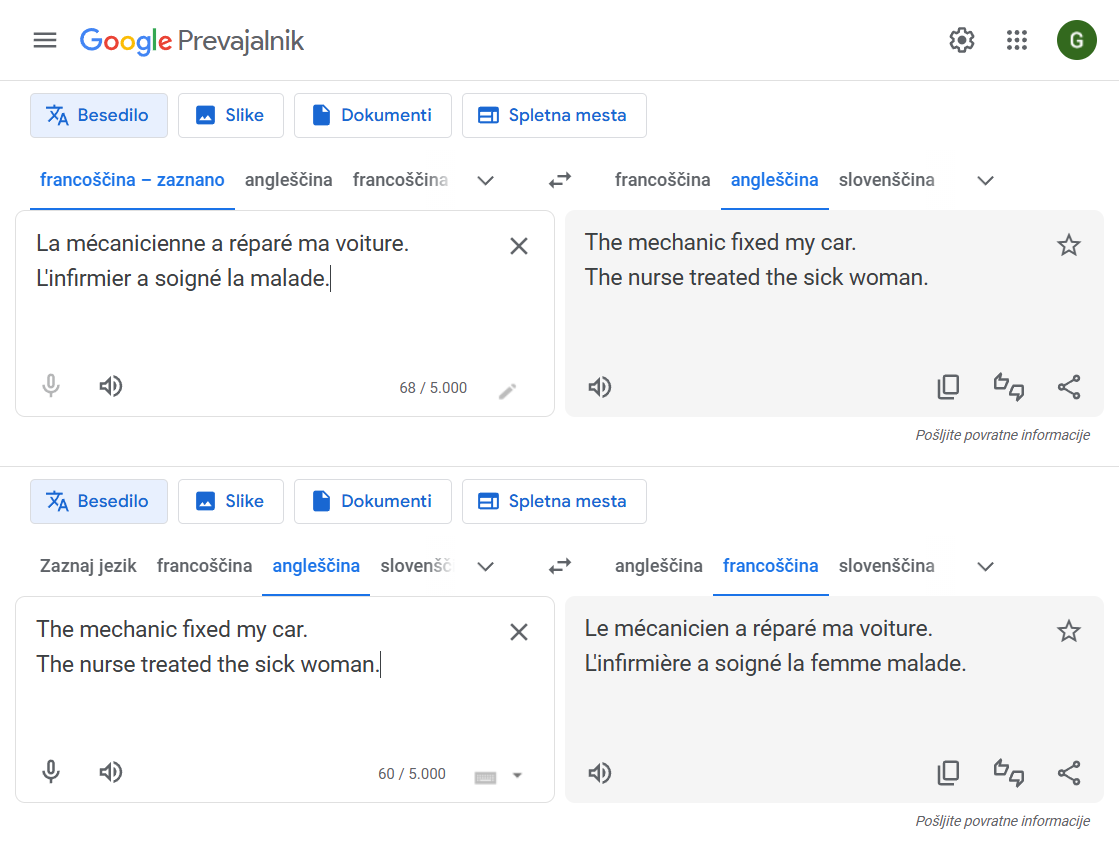
Google Prevajalnik se uči prevajati s pomočjo interneta. Z rudarjenjem podatkov se uči iz informacij, prosto dostopnih na spletu. Poleg jezika se UI nauči, na primer, da je med mehaniki več moških kot žensk, med zdravstvenimi tehniki pa več žensk kot moških. UI ni sposobna razlikovati med tem, kaj je »resnica« in kaj je posledica stereotipov in drugih predsodkov. Na ta način Google Prevajalnik promovira in širi informacije o vsem, kar se nauči, in s tem še bolj utrdi stereotipe.
Oglejmo si primer, ki ga prikazuje slika. Ko s pomočjo Google Prevajalnika prevedemo besedilo iz francoščine v angleščino in nato ponovno nazaj v francoščino, se mehanik (v ženskem spolu) spremeni v mehanika (v moškem spolu) in medicinski tehnik (v moškem spolu) v medicinskega tehnika (v ženskem spolu).
Težave se v delovanje UI prikradejo takrat, ko se posamezen primer razlikuje od večine (ne glede na to, ali gre zares za večino v resničnem svetu, ali le za večino po podatkih interneta).
Aktivnost
Poskusi v Google Prevajalniku izslediti kakšen stereotip. Poigraj se s prevajanjem v različne jezike in iz njih. S klikom na dve puščici med obema poljema obrni smer prevajanja.
Nekateri jeziki, na primer turščina, ne poznajo slovnične kategorije spola. Pri prevajanju iz turškega jezika in v turščino se pokažejo številni stereotipi. V turščini in v številnih drugih jezikih je namreč nakazana moška spolna nevtralnost (raba moških generičnih oblik v položajih, ko so mišljeni osebki obeh spolov) kot odraz »naravnega« jezikovnega stanja. V zgornjem primeru je nenavadno to, da se spremeni spol samostalnika pri prevodu iz angleščine v francoščino.
Sistemi UI lahko pripravijo različne napovedi, priporočila ali odločitve. Verjetnost napovedi je pogosto izražena v odstotkih. Ta številka nam pove, kako verjetne so po lastni oceni sistema UI njegove napovedi.
Po svoji naravi so lahko napovedi napačne. Velikokrat so napake sprejemljive, v nekaterih primerih pa ne. Poleg tega obstaja veliko različnih načinov izračunavanja stopnje napake, po različnih merilih – in programer izbere tisto, ki se mu zdi najprimernejša. Pogosto se zanesljivost napovedi spreminja glede na značilnosti vhodnih podatkov.