Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
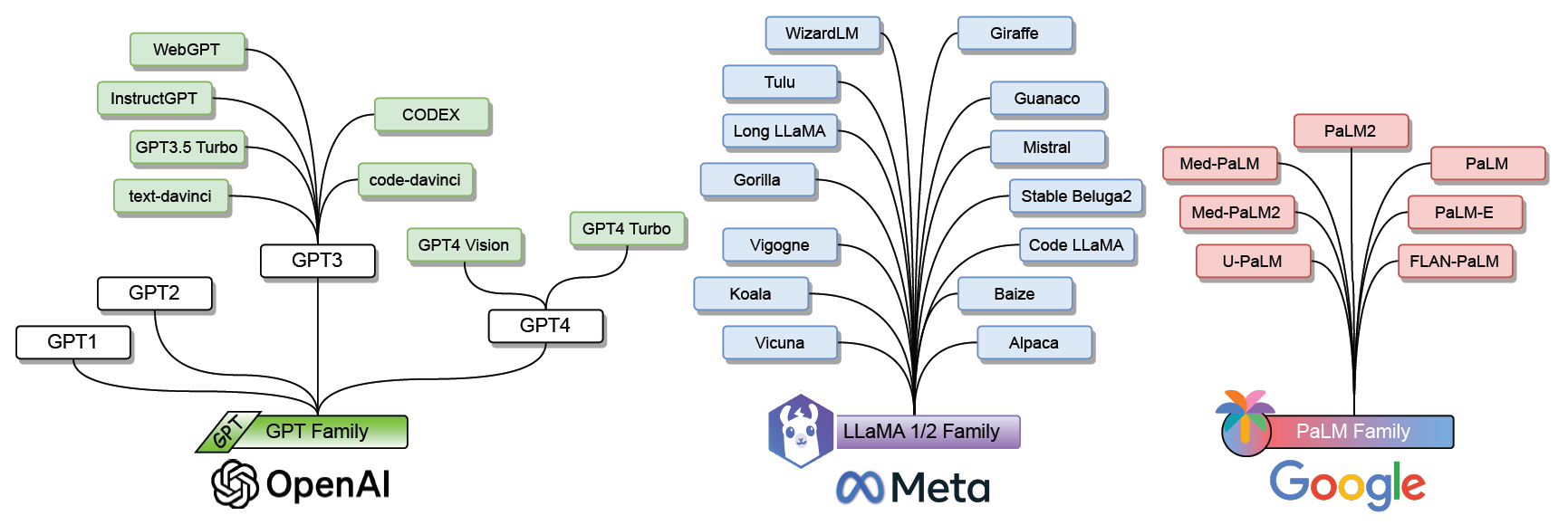
Družine velikih jezikovnih modelov (LLM)
Generativna umetna inteligenca
V središču uporabe generativne UI so veliki jezikovni modeli (LLM) ali slikovni oziroma difuzijski modeli (ang. diffusion models). Kot je dejal jezikoslovec Noam Chomsky »grobo rečeno, [veliki jezikovni modeli] iščejo vzorce v ogromnih količinah podatkov in postajajo vse bolj spretni pri ustvarjanju statistično verjetnih rezultatov – kot sta, vsaj tako se zdi, človeškemu podoben jezik in način razmišljanja.« BERT, BLOOM, GPT, LLaMA in PaLM so vsi veliki jezikovni modeli. Slikovni modeli globokega učenja pa se imenujejo difuzijski modeli. Stable diffusion in Midjourney sta priljubljena primera slednjih.
Podjetje, ki je produkt razvilo, ali tretja oseba, lahko model LLM dodatno usposobi (natančno uravna) za posebne naloge, npr. za odgovarjanje na vprašanja ali povzemanje esejev. Lahko pa modelu LLM ali klepetalnemu robotu dodajo nekaj pozivov ali ga nadgradijo z obsežnim programiranjem ter nato rezultat predstavijo kot aplikacijski paket (Chatpdf, Elicit, Compose AI, DreamStudio, NightCafe, PhotoSonic, Pictory ...).
Na ta način je OpenAI natančno uravnal svoj GPT3 in GPT4 z vzorci vprašanj in odgovorov ter s pravili o sprejemljivosti vsebine in tako je nastal ChatGPT. Googlova raziskovalna ekipa je učila model PaLM z znanstvenimi in matematičnimi podatki in nastala je Minerva. Ta jezikovni model je dosegel najboljše rezultate med aplikacijami jezikovnih modelov za reševanje kvantitativnih problemov sklepanja: rešiti je znal skoraj tretjino problemov na dodiplomski ravni v fiziki, biologiji, kemiji, ekonomiji in drugih vedah, ki zahtevajo kvantitativno sklepanje.
Dejstvo, da je bil jezikovni model natančno uravnan za določeno nalogo ali pa ne, bo vplivalo na njegovo učinkovitost pri tej nalogi. Glede na to, ali celoten paket zagotavlja eno samo podjetje (na primer OpenAI je lastnik ChatGPT), ali pa je model nadalje razvijalo drugo podjetje, vpliva na varnost in zasebnost podatkov. Ko raziskuješ kateri model bi uporabil(-a), se splača preučiti tako uspehe kot omejitve izbranega modela.
Če se odločiš za uporabo generativne UI, moraš biti pozoren(-na) na njene napake in pomanjkljivosti ter biti pripravljen(-a), da jih odpraviš. Te napake vključujejo:
- Netočnosti v vsebini, saj jezikovni model ni banka znanja ali iskalnik. Celo najnovejši modeli halucinirajo in navajajo dejstva in vire, ki so izmišljeni.
- Pristranskost, ki se prikrade zato, ker so tudi podatki, na katerih so se ti modeli učili, vsebovali predsodke (pristranskost).
- Učinkovitost, ki je zelo odvisna od uporabljenih iztočnic (vprašanj, pozivov), uporabniške zgodovine in včasih od nepredvidljivih dejavnikov.
Čeprav lahko generativna UI zmanjša obremenitev uporabnikov in pomaga pri določenih nalogah, temelji na statističnih modelih, ki so nastali na podlagi ogromnih količin spletnih podatkov. Ti podatki ne morejo nadomestiti resničnega sveta, življenjskih okoliščin (kontekstov) in odnosov. ChatGPT ne more opisati konteksta ali razložiti, kaj dejansko vpliva na uporabnikovo vsakdanje življenje. Ne more ponuditi novih idej ali rešitev za izzive v resničnem svetu.
Zmogljivost generativne UI ni niti blizu zmožnostim človeškega uma – še posebej v smislu tega, kar lahko človek razume in naredi z omejenimi podatki.
»Največja pomanjkljivost generativne UI je sicer odsotnost najbolj ključne zmogljivosti kakršnekoli inteligence: povedati ne le, kaj se dogaja, kaj se je zgodilo in kaj se bo zgodilo – to je opisovanje in napovedovanje – temveč tudi, kaj se ni zgodilo ter kaj bi se lahko zgodilo in kaj se ne bi moglo zgoditi.«Noam Chomsky, Ian Roberts in Jeffrey Watumull