Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
Obdelava naravnega jezika
Dekodiranje
Dekodiranje (ang. decoding) je proces, pri katerem algoritem sprejme vhodno zaporedje (v obliki signala ali besedila) in na podlagi informacij, ki jih vsebuje model, sprejme odločitev, pogosto v obliki izhodnega besedila. Pri tem je treba upoštevati določene zakonitostmi algoritmov: transkripcija in prevajanje morata običajno potekati v realnem času, zato je pri tem ključno vprašanje zmanjševanje časovnega zaostanka. Prostora za delovanje UI je tu veliko.
Celovit pristop
Procese ločenega ustvarjanja in kasneje kombiniranja teh komponent je danes nadomestil celovit pristop, pri katerem sistem zapiše / prevede / interpretira vhodne podatke s pomočjo edinstvenega modela. Trenutno se taki modeli učijo s pomočjo izjemno zapletenih globokih nevronskih mrež: največji model GPT3 naj bi obsegal več sto milijonov parametrov.
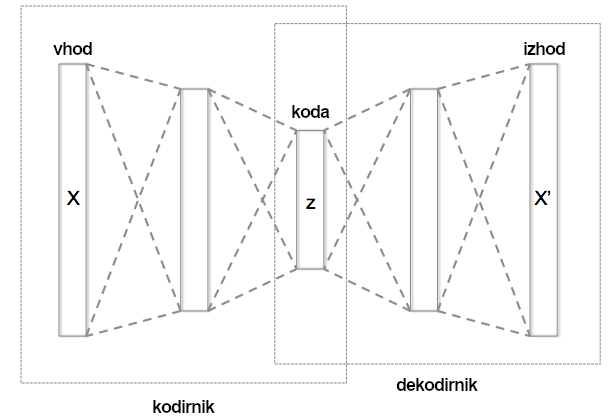
Poskusimo poenostaviti: recimo, da imamo določene podatke. Te surove podatke lahko na poljuben način zakodiramo. Toda kodiranje je lahko redundantno in morda celo zelo drago. Zato izdelamo posebno napravo, samodejni kodirnik (ang. autoencoder) – glej sliko. Stroj izvorno besedilo prenese v majhen vektor (kodirnik), nato pa vektor razširi (dekodirnik) in ponovno vzpostavi besedilo, ki je nekako blizu izvornemu besedilu. Ideja je v tem, da ta mehanizem ustvari zelo koristen vmesni vektor – zaradi dveh zaželenih lastnosti: je majhen, in »vsebuje« informacije o izvornem besedilu.
Prihodnost
Verjetno bodo takšni celoviti pristopi kmalu omogočali, da bo vmesnik (1) slišal in prepoznal, kateri jezik govorite, (2) zapisal izgovorjeno besedilo, (3) ga prevedel v jezik, ki ga ne poznate, (4) usposobil sistem za sintezo govora za prepoznavanje vašega glasu in (5) z vašim glasom prebral ustrezno prevedeno besedilo v drugem jeziku.
Na posnetkih spodaj si oglejte dva primera, ki so ju zasnovali raziskovalci na Universidad Politecnica de Valencia v Španiji, v katerih je za sinhronizacijo uporabljen model lastnega glasu govorca.