Licenca
To delo je na voljo pod pogoji slovenske licence Creative Commons 2.5:
priznanje avtorstva - nekomercialno - deljenje pod enakimi pogoji.
Celotna licenca je na voljo na spletu na naslovu http://creativecommons.org/licenses/by-nc-sa/2.5/si/. V skladu s to licenco je dovoljeno vsakemu uporabniku delo razmnoževati, distribuirati, javno priobčevati, dajati v najem in tudi predelovati, vendar samo v nekomercialne namene in ob pogoju, da navede avtorja oziroma avtorje in izdajatelja tega dela. Če uporabnik delo predela, kar pomeni, da ga spremeni, preoblikuje, prevede ali uporabi to delo v svojem delu, lahko predelavo dela ponudi na voljo le pod pogoji, ki so enaki pogojem iz te licence oziroma pod enako licenco.
![]()
Kodna tabela
Poudariti moramo, da so kodne tabele, kot na primer ASCII, Unicode in druge, v bistvu le dogovori. Mnogi zgodnji računalniki niso upoštevali teh dogovorov, saj so njihovi izdelovalci menili, da jim bo to omogočilo izdelavo elegantnejšega in učinkovitejšega sistema. Vsakdo namreč lahko ustvari svojo kodno tabelo – spodaj je izmišljen primer 7-bitne kodne tabele (na primer Slokod), ki izhaja iz slovenskega jezika.
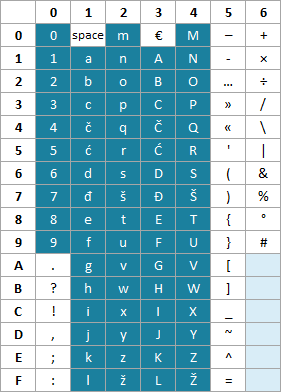
Danes, ko so skoraj vsi računalniki priključeni v omrežje, je drugače. Zelo pomembno je, da se držijo istega standarda. Sicer se lahko besedilo, ustvarjeno na enem računalniku, pojavi kot zaporedje nesmiselnih znakov na drugem računalniku. To se lahko kljub temu zgodi, na primer, ko prejmeš e-poštno sporočilo z besedilom, ki je kodirano s standardom, ki ni privzet in ni pravilno označen v glavi e-pošte. Ker e-poštni program poskuša dekodirati besedilo z napačnim standardom, lahko določene znake prikaže popolnoma napačno.
Huffmanovo kodiranje
Običajen način stiskanja podatkov je, da bolj pogostim stvarem priredimo krajše kode, bolj redkim pa daljše kode. Na primer, v Morsejevi kodi priredimo črki e eno piko, črki z pa dve črtici, ki jima sledita dve piki – torej štiri simbole. V povprečju je to bolje, kot da bi vsaki črki priredili enako dolgo kodo.
Vendar je prirejanje optimalne dolžine kod posameznim črkam težje, kot se zdi na prvi pogled – toliko težje, da nihče ni mogel izdelati algoritma za izračun najbolj optimalnih kod, dokler ni to leta 1951 uspelo študentu Davidu Hoffmanu. Njegov dosežek je bil tako pomemben, da mu ni bilo treba pisati zaključnega izpita.
Tehnika Huffmanovega kodiranja je zadnja stopnja številnih metod stiskanja podatkov, vključno z JPEG, MP3 in ZIP. Osnovna ideja Huffmanovega kodiranja je, da vzamemo nabor »simbolov« (ki so lahko znaki v besedilu, dolžine v RLE, vrednosti kazalcev v sistemu Ziv-Lempel ali parametri pri stiskanju z izgubami) in zagotovimo optimalne vzorce bitov, s katerimi predstavimo te »simbole«. Huffmanovo kodiranje običajno povezujemo s stiskanjem besedilnih dokumentov in, čeprav lahko to počne razmeroma dobro, deluje še veliko bolje v kombinaciji s kodiranjem Ziv-Lempel (glej v nadaljevanju).
Začnimo z zelo preprostim besedilnim primerom. Jezik tega primera uporablja le 4 različne znake in je za nas izjemno pomemben: to je jezik, ki ga uporabljamo za predstavitev DNK. DNK je sestavljena iz zaporedij štirih znakov A, C, G in T. Na primer, zaporedje DNK bakterije E. coli, ki vsebuje okoli 4,6 milijona znakov, se začne z zaporedjem:
agcttttcattct
Pri enostavni predstavitvi s štirimi znaki pričakujemo, da bomo lahko vsak znak predstavili z dvema bitoma, na primer:
a: 00 c: 01 g: 10 t: 11